Alibek ZhakubayevI am a PhD Candidate in Computer Science at Baylor University, advised by Dr. Greg Hamerly. My dissertation work aims to accelerate the k-means clustering algorithm while preserving its quality. This involves the integration of probability, geometric heuristics, and dimensionality reduction techniques to improve the efficiency of the k-means process. In addition to my dissertation, I am part of Dr. Benton's bioinformatics lab, where we apply machine learning techniques to study the effects of alcohol on bones. I earned my Undergraduate and Master's degrees in Computer Science from Nazarbayev University. Dr. Adnan Yazici was my advisor during my Master's studies, where my thesis focused on real-time activity recognition. Email / GitHub / Google Scholar / LinkedIn |

|
ResearchI focus on optimizing the k-means clustering algorithm, developing techniques to enhance computational efficiency while maintaining high accuracy. In bioinformatics, I apply machine learning models to analyze the effects of alcohol on skeletal health and biochemical markers. |
|
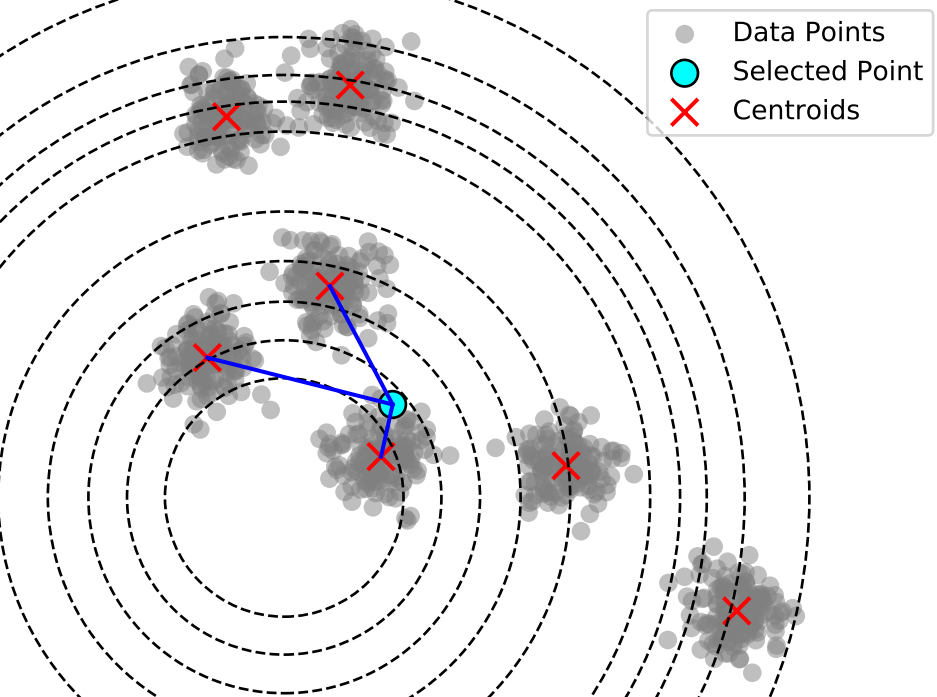
Beta k-means: Accelerating k-means Using Probabilistic Cluster FilteringAlibek Zhakubayev, Greg Hamerly The 11th IEEE International Conference on Data Science and Advanced Analytics (DSAA), 2024 The paper proposes Beta k-means and Beta Hamerly k-means algorithms, which use probabilistic filtering with a beta distribution to skip unnecessary distance calculations during clustering. These methods show faster convergence than traditional k-means, Hamerly, and Annulus algorithms, especially with high-dimensional data, without sacrificing clustering quality |
|
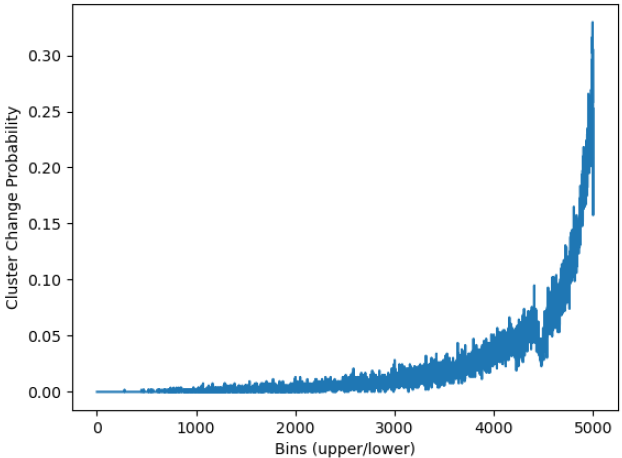
Using Annealing to Accelerate Triangle Inequality k-meansAlibek Zhakubayev, Greg Hamerly The 11th IEEE International Conference on Data Science and Advanced Analytics (DSAA), 2024 The paper presents an annealing-based technique to speed up Hamerly’s and Elkan’s k-means algorithms by skipping distance calculations for points less likely to change assignments. Experimental results show that this technique can reduce execution time by up to 15% without compromising clustering quality, especially in high-dimensional datasets |
|
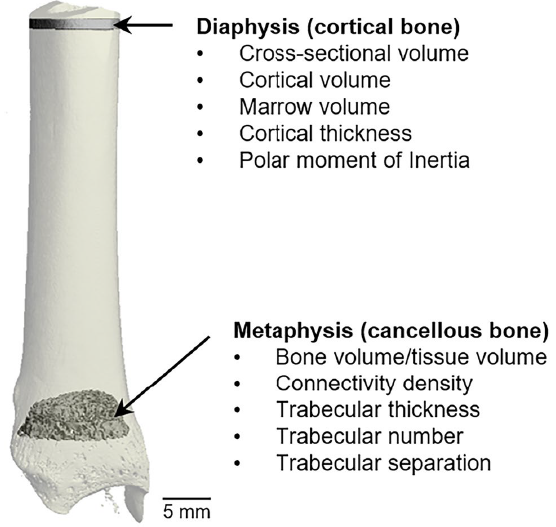
Ethanol consumption in non-human primates alters plasma markers of bone turnover but not tibia architectureAlibek Zhakubayev, Lara Sattgast, Anne Lewis, Kathleen Grant, Russell Turner, Urszula Iwaniec & Mary Lauren Benton Scientific Reports, 2024 This study explores the impact of chronic ethanol consumption on non-human primates, finding that ethanol significantly lowers plasma markers of bone turnover, such as osteocalcin and CTX, but does not alter tibial bone architecture. Using machine learning and statistical analysis, the research suggests that the decrease in bone turnover may impair bone quality, though bone structure remains unaffected |
|
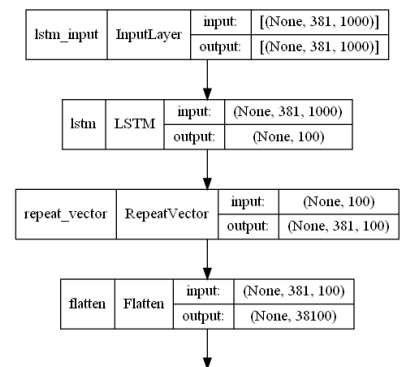
Image processing approach provides robust feature extraction for classification with small sample sizesAlibek Zhakubayev, Thomas Andersen, Annie Vesterby, Lene Warner Thorup Boel, Kathleen Grant, Urszula Iwaniec, Russell Turner, Erich Baker, Mary Lauren Benton The 7th International Conference on Information System and Data Mining (ICISDM), 2023 This study uses an LSTM-based encoder-decoder model to extract features from µCT images, enabling the classification of bone samples by sex, age, and alcohol consumption status in humans and rhesus macaques. The LSTM-derived features allowed moderate classification accuracy for sex, with 72% accuracy in macaques and 65.5% in humans, while distinctions based on alcohol consumption were less pronounced |

|
Clustering Faster and Better with Projected DataAlibek Zhakubayev, Greg Hamerly The 6th International Conference on Information System and Data Mining (ICISDM), 2022 This paper proposes a method to speed up k-means clustering by first applying random projections to reduce data dimensionality, clustering in this reduced space, and then refining the clustering in the original high-dimensional space. This approach achieves faster convergence while maintaining clustering quality, especially for high-dimensional datasets, when compared to standard methods like Hamerly’s k-means |
|
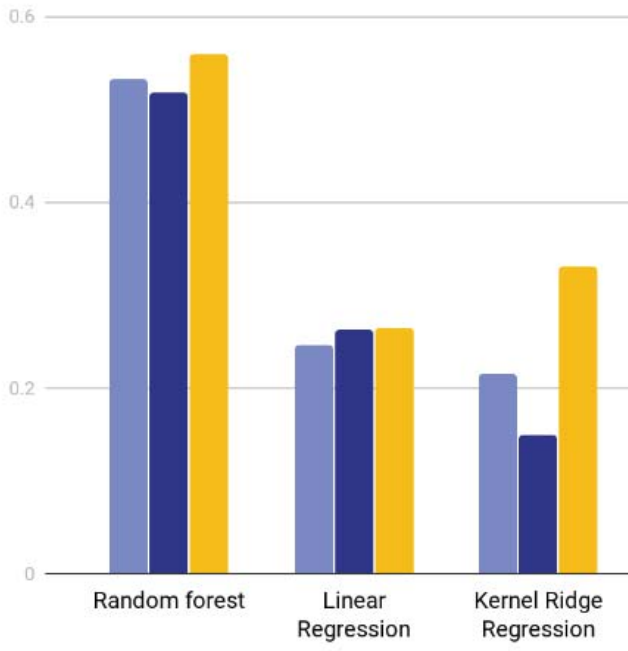
Learning the Relationship between Asthma and Meteorological Events by Using Machine Learning MethodsAlibek Zhakubayev, Adnan Yazici The 13th International Conference on Application of Information and Communication Technologies (AICT), 2019 This study develops a machine learning model to predict asthma cases based on meteorological events, using data from Russia to identify significant features and applying the findings to Kazakhstan through transfer learning. Random forest regression, using both original and semi-synthetic features, proved most effective, highlighting the influence of weather patterns on asthma prevalence across regions |
|
Adapted from Leonid Keselman's fork of Jon Barron's website |